Stable Diffusion Web UIのtxt2imgを使って遊んでみるお話。

はじめに
いわゆる生成AIと呼ばれる物体を触ってみるお話。
Stable Diffusion Web UIを、とりあえず使えるようになったけど、細かい設定とかがよくわからないってな人向け。
こういうのを触りたい人ってのは、とりあえずちょっとは開発のようなものが出来るか分るかの人だと思うので、初歩的なお話はかなり端折ってるし、何よりも説明が雑です。なにとぞ。
よくわからんってことは、てきとーに調べてね。
Stable Diffusion web UIってなによ
Stability AIが出してる学習済みAIモデルと呼ばれるものを、AUTOMATIC1111って人がブラウザ上で簡単に触れるようにした物体。
テキストや画像から連想される画像なんかを生成してくれるです。
厳密には、画像を生成してるわけではなく、関数を生成してるわけなんだけど、そのあたりをお話すると長くなるので割愛。
以後、「画像の生成」と言いますが、技術的にはたぶんあまり正しくないです。
前提条件
- Stable Diffusion Web UIを、ローカルで使えるようになっているPC
Stable Diffusion Web UI
「はじめに」でも紹介したけれど、画像を生成してくれる物体です。
この記事ではすでにローカル環境にセットアップが完了していることを想定しています。
まだセットアップが完了していない人は、下記をご参照ください。

サンプラーの設定
細かい理論的なところはさておき。
Stable Diffusion自体が、ノイズ画像から、モデルを基に計算した「predicted noise」を減算しながら画像を生成している。
そのノイズの除去の方法をコントロールする項目。
使用するモデルごとに向き不向きがあるので、そこに従うのがよろしいかと思うが、それぞれのサンプリングの過程を理解することは、有用に思う。
こういうシステムにおいての、基礎がここに詰まっているといっても過言ではないので、詳しく説明する。

Sampling method
ノイズの減算過程のロジックを決定する。
ここを変更することで、同一checkpoint・同一seedでも、「似ているが、少し違う」出力を得ることができるかもしれない。
基本的には、使用するモデルごとに向き不向きがあるので、指定されたものを使用するとよいが、ここのコントロールをうまく行えると、やみくもにseed回さなくてもよくなるかもしれない。
Schedule type
ノイズ除去のスケジュールをいつどのように行うかを決定する。
基本的に「Automatic」を選んでおけばよいと思うが、これも、どのような方法をとっているかを知っておいて損はないと思う。
Sampling steps
上記2種の項目で決定した減算方法を、何回行うかを決定する。
一般に、ステップが増えるだけ生成の精度が上がるが、時間がかかる。
また、十分に減算されつくした画像では、Stepを上げても変化が少なくなる傾向にある。
Sampling methodによる出力変化
ノイズ減算の過程と、methodによる違いを、以下に示します。
Sampling methodごとにSampling stepを増減させています。
Stepが進むにつれ画像が「完成していく」のが見て取れるかと思います。
また、methodによって「完成」までの過程が異なることにも留意するとよろしいかと思います。
用語の理解用
サンプリング付近でよく出てくる単語たち
| 語 | なにそれ | 備考 | 言葉の意味 |
|---|---|---|---|
| SDE | 確立微分を使用する。 | 通常はODE(Ordinary Differential Equation):常微分を使用 | Stochastic Differential Equation |
| a | ステップごとに普通よりも多めにノイズを除去し、その後ノイズを追加する。 | 一般に「収束しづらい」「画質があがる」などと表現されるのは、このノイズを追加するという数式による効果。 | ancestral sampling |
| Heun | オイラー法による微分後にノイズ平均をとってさらに更新してる。 | 計算時間が増えるが精度が向上する。 | そのままHeun |
なお、サンプラーの命名規則は以下の通り。別に知らなくても使えると思うので参考程度だが、選ぶときに楽になる。
たとえば、よく似た名前DPM2 aとDPM++2S aとDPM++2M SDE Heunを比較する。
| ベース | isModified | 計算の次元 | パス数 | etc | 意味 |
|---|---|---|---|---|---|
| DPM | 2 | a | Diffusion Probabilistic Models-solverの、2次元計算の、ancestral samplingをする | ||
| DPM | ++ | 2 | S | a | Diffusion Probabilistic Models-solverの ++ (改良版)で、2次元計算の、Singleパスで、ancestral samplingをする |
| DPM | ++ | 2 | M | SDE, Heun | Diffusion Probabilistic Models-solverの ++ (改良版)で、2次元計算の、Multiパスで、Stochastic Differential Equation(確立微分)をする・Heunする |
Schedule typeはすべて「Normal」を選択しています。


DPM++ 2M

DPM++ 2M SDE

DPM++ 2S a

cat, masterpiece, best quality,((ultra detailed))
Negative prompt: error, jpeg artifacts, lowers, blurry, bokeh, abstract, multipul angle, two shot, split view, grid view,
(watermark, username, artist name, stamp, title, subtitle, date, footer, header), ((text, signature)), low quality, worst quality, out of focus,
Steps: 2, Sampler: DPM++ 2M SDE, Schedule type: Karras, CFG scale: 7, Seed: 869806953, Size: 512x512, Model hash: e12177c4b0, Model: himawarimix_v11, Version: v1.10.1
Schedule typeによる出力変化
同一ロジックであっても、その減算のタイミングを変化させることで異なる出力を得ることが可能となります。
先ほどは、methodによる減算の違いでしたが、今度は、同一methodにおけるSchedule typeの比較です。
「完成」に近づく速度に注目するとよろしいかと思います。
用語の理解用
| 語 | なにそれ | 備考 | 言葉の意味 |
|---|---|---|---|
| Automatic | サンプラーによっていい感じに選んでくれる | 基本はこれでいいと思う | 自動 |
| Normal | 等分にノイズを除去。一番普通なやり方 | ふつう。 | 普通!! |
| Exponential | 後半になるにつれ増大。最後の精度を上げてる。 | マルチパスのものと相性がよいといわれる | 指数関数的 |
| Karras | 中間ステップを飛ばす。最初と最後の精度を上げてる。 | SDE(確立微分)のモデルに相性が良いといわれる | Karrasって人が思いついたらしい |
DPM++ 2M SDE (Normal)
DPM++ 2M SDE (Exponential)

DPM++ 2M SDE (Karras)

Hires. fix
簡単にいえば、アップスケールするためのオプション機能。
学習データが小さいなどの影響により、出力画像が破綻する場合などに用いる。

Upscaler
アップスケールするアルゴリズムを決定する。
数が多いので内容については割愛。ここの値を変更することで、出力される結果が少し変わる。
なお、プリインストールされているもののほかにも追加することが可能。
気に入る結果が得られない場合は、アップスケーラ探しをしてもよいかもしれない。
Upscale by
アップスケールする倍率を決定する。
2を指定すれば、もともと指定しているWidthおよびHeightの2倍にアップスケールされた画像を出力する。
Hires steps
アップスケールするステップ数を決定する。
ステップを増やだけ緻密になるが、時間がかかる。0を使用することで、Sampling stepsと同じ数が適用される。
ただし、Sampling stepsが十分に高い場合は、画像への影響は限定的なため、txt2imgを使用する限りにおいて、0でよいと思う。
Denoising strength
アップコンバートした際のノイズ除去の強さを決定する。
値を上げすぎたり下げすぎたりするとオリジナル画像からズレた画像が出力される。
概ね0.5-0.7程度で使用するのがよいとされるが、hires使用時の出力された画像が気に入らない際にいじるといい。
以下に、UpscalerとDenoising strengthを調整した比較画像を示す。
Denoising strengthを0.8にすると、必ずまつげが変色しハートが出てくるのはなんなのか・・・

Refiner
主たるモデルたる「Stable Diffusion checkpoint」に加え、サブで違うモデルを組み合わしたうえで、その画像を混ぜるような機能です。
・・・ですが、モデルのバランスが崩壊することが多く、txt2imgを使っている限りにおいては、使いどころが極めて難しいです。

Checkpoint
サブで使用するモデルを決定します。
swich at
各モデルの混合具合を決定します。
0に近ければ近いほどサブ寄りに、1に近ければ近いほど主モデルに近い絵となります。
なお、下記結果は、VAEの設定や、その他調整が甘いという要因はあるので、この結果をもって一概にダメだというわけではないです。
・・・ですが、どうやっても難しいです。

Batch count / Batch size
「Batch count」および「Batch size」は、同じプロンプトで、複数の結果を出力したいときに使用するオプションです。
ただただ、複数出力するというだけなので、詳細な説明は割愛します。
大きな数値を指定すると負荷が大きいかもしれないので、適度な数値を入れて使ってみてください。
Batch count
指定した数だけ画像を生成してくれます。
Batch size
一度の生成で、この値の数だけ並列処理してくれます。構図の調整なんかをしたい場合には、RAMの許す限りこの値を大きくすることで、時短ができることになります。
CFG Scale
プロンプトへの忠実度を決定する値。
0に近づくほど、プロンプトを空にした状態での出力に近づき、値を大きくするにつれ、プロンプトへの忠実度が上がります。
「惜しいけど思ったのと違う」というようなときにいじってみるとよいかと思いますが、基本的に5-8付近でちょうどよい塩梅となることが多いです。

学習データが、おそらく、こういった絵だったのでしょう。

Seed
出力条件のランダム性を制御する値。
この記事最初の方から、当然の如く「Seedを固定」と書いてますが、ここの項目のことです。
同一checkpointで、同一promptで、同一Seedであれば、同一の出力を得ることができます。
※ただし、前述のとおり、サンプラーの設定によっても変化はあります。
なお、インプットの横の🎲️ボタンを押すまたは値を-1とすると、ランダマイズされます。
また、♻️ボタンを押すと、直前のseed値がインプットに表示されseedが固定されます。同一条件下において同一出力を得ることができます。


ADetailer
ここまでの条件で生成した画像をもとに、さらに顔や身体などを検出し、ピンポイントで修正を掛ける機能。
構図をそのままに、表情や服などを変更したり、表情の書き込みを追加したり、あるいは背景を違うものに差し替えるなどの処理が行える。
ADetailer modelとADetailer promptが基本機能。
その下のオプション:DetectionやMaskPreprocessingおよびInpaintingを使うことで、やれることが増える、というようなイメージ。
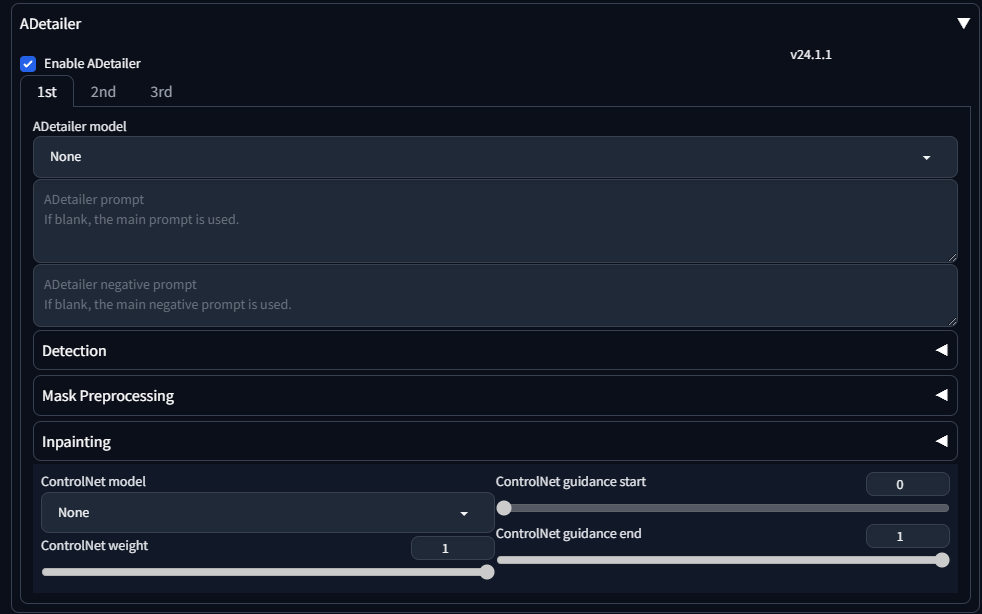
ADetailer model
何を検出するかのモデルを決定します。
最初から入っているモデルは、以下の通り。何を検出したいかによって選ぶとよいです。
| モデル名 | 検出の対象 | 対象 |
|---|---|---|
| face_yolov8n.pt | 顔 | 2D/リアル |
| face_yolov8s.pt | 顔 | 2D/リアル |
| hand_yolov8n.pt | 手 | 2D/リアル |
| person_yolov8n-seg.pt | 人の全体 | 2D/リアル |
| person_yolov8s-seg.pt | 人の全体 | 2D/リアル |
| mediapipe_face_full | 顔 | リアル |
| mediapipe_face_short | 顔 | リアル |
| mediapipe_face_mesh | 顔 | リアル |
ADetailer prompt / ADetailer negative prompt
上記モデルで検出した箇所の修正を施すためのプロンプトを入力する箇所です。
真ん中の画像内「face 0.88」とあるのが、検出した箇所とその精度です。

neonpunk, city, shoes, girl, long hair,, masterpiece, best quality,((ultra detailed)), cute face, beautiful detailed eyes,, beautiful illustration,
Negative prompt: low quality, worst quality, out of focus,, error, jpeg artifacts, lowers, blurry, bokeh, abstract, multipul angle, two shot, split view, grid view, (worst quality:1.4), (low quality:1.4), watermark, username, artist name, stamp, title, subtitle, date, footer, header), ugly, missing arms, extra_arms, mutated hands, extra_legs, bad hands, bad anatomy, deformed mutated disfigured, long_neck, long_body, longbody, poorly_drawn_hands, malformed_hands, missing_limb, floating_limbs, disconnected_limbs, poorly drawn fingers, (extra_fingers, bad fingers, liquid fingers, missing fingers, extra digit, fewer digits ) ugly face, deformed eyes, partial face, partial head, bad face, inaccurate limb, cropped, ghost, ((text, signature))
Steps: 40, Sampler: DPM++ 2M SDE, Schedule type: Karras, CFG scale: 5, Seed: 1741452187, Size: 1024x512, Model hash: e12177c4b0, Model: himawarimix_v11, VAE hash: 63aeecb90f, VAE: ClearVAE_V2.3_fp16.pt, Version: v1.10.1
Detection
検出の精度や範囲などのコントロールを行う箇所。

Detection model confidence threshol
検出の信頼性に対して、足切りラインを設定する。
初期値は0.3となっており、これは、検出モデルによる信頼性が0.3を下回る際には対象から外すという処理となる。
Mask only the top k largest (0 to disable)
検出の面積の上位何個までを対象とするかを決定する。
たとえば、2といれれば検出面積の広い順に2つが対象とされる。
一点透視を考慮するなれば、「近い物から何個まで」というように読み替えてもよいかもしれない。
Mask min area ratio
オリジナルの画像に対して検出した面積の比率に、足切りラインを設定する。
つまり、Mask max area ratioの逆である。
0.1を指定すれば、オリジナルの画像に対して10%を下回る検出エリアを対象から外す処理となる。
一点透視を考慮するなれば、「どれだけ近い物を対象とするか」という風に読み替えてもよいかもしれない。
Mask max area ratio
オリジナルの画像に対して検出した面積の比率に、上限ラインを設定する。
つまり、Mask min area ratioの逆である。
0.5を指定すれば、オリジナルの画像に対して50%を上回る検出エリアを対象から外す処理となる。
一点透視を考慮するなれば、「どれだけ遠い物を対象とするか」という風に読み替えてもよいかもしれない。

neonpunk, city, (3 girls:1.4), perspective, masterpiece, best quality,((ultra detailed)), cute face, beautiful detailed eyes,, beautiful illustration,
Negative prompt: low quality, worst quality, out of focus,, error, jpeg artifacts, lowers, blurry, bokeh, abstract, multipul angle, two shot, split view, grid view, (worst quality:1.4), (low quality:1.4), watermark, username, artist name, stamp, title, subtitle, date, footer, header), ugly, missing arms, extra_arms, mutated hands, extra_legs, bad hands, bad anatomy, deformed mutated disfigured, long_neck, long_body, longbody, poorly_drawn_hands, malformed_hands, missing_limb, floating_limbs, disconnected_limbs, poorly drawn fingers, (extra_fingers, bad fingers, liquid fingers, missing fingers, extra digit, fewer digits ) ugly face, deformed eyes, partial face, partial head, bad face, inaccurate limb, cropped, ghost, ((text, signature))
Steps: 50, Sampler: DPM++ 2M SDE, Schedule type: Exponential, CFG scale: 5, Seed: 4033847217, Size: 1024x512, Model hash: e12177c4b0, Model: himawarimix_v11, VAE hash: 63aeecb90f, VAE: ClearVAE_V2.3_fp16.pt, Denoising strength: 0.4, ADetailer model: face_yolov8n.pt, ADetailer prompt: "cute face, beautiful detailed eyes", ADetailer confidence: 0.3, ADetailer dilate erode: 4, ADetailer mask blur: 4, ADetailer denoising strength: 0.4, ADetailer inpaint only masked: True, ADetailer inpaint padding: 32, ADetailer model 2nd: person_yolov8n-seg.pt, ADetailer prompt 2nd: lower building, ADetailer confidence 2nd: 0.3, ADetailer dilate erode 2nd: 4, ADetailer mask merge invert 2nd: Merge and Invert, ADetailer mask blur 2nd: 4, ADetailer denoising strength 2nd: 0.4, ADetailer inpaint only masked 2nd: True, ADetailer inpaint padding 2nd: 32, ADetailer version: 24.1.1, Hires upscale: 1, Hires steps: 50, Hires upscaler: R-ESRGAN 4x+ Anime6B, Mask blur: 4, Inpaint area: Only masked, Masked area padding: 32, Version: v1.10.1
Mask Preprocessing
検出した範囲自体の位置をコントロールする箇所。
より細かく調整したい場合に使用するものたち。そんなに頻繁に使うものでもないとおもう。
ただ、背景だけを修正したいというような要求には、Mask marge modeの設定が強力。
のちほどInpaint併用での例を挙げます。
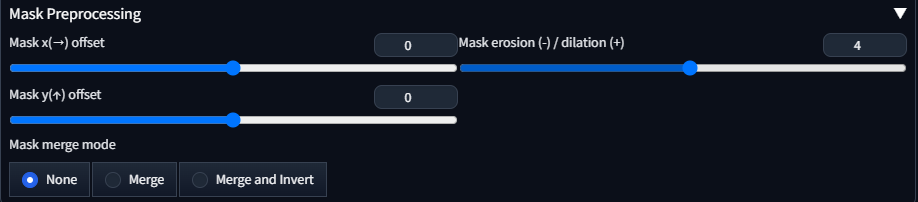
Mask x(→) offset / Mask y(↑) offset
検出した範囲をX軸方向またはY軸方向にずらす。
検出がおおむね正解だが、なんか惜しいって時の微調整用。
Mask erosion (-) / dilation (+)
検出した範囲の大きさをコントロールする。
正の数を入れると拡大・負の数で縮小する。
Mask merge mode
検出した範囲を統合/反転します。
たとえば、person_yolov8n-seg.ptで人の全体を選択したうえで、反転すれば、背景だけを選択する、などの用途で使える。
| モード | 何? |
|---|---|
| None | 何もしない |
| Marge | 複数のマスクを1つにまとめる |
| Marge and Invert | マスクを1つにまとめて反転する |
Inpainting
検出した範囲を、どのように書き直しするかをコントロールする箇所。
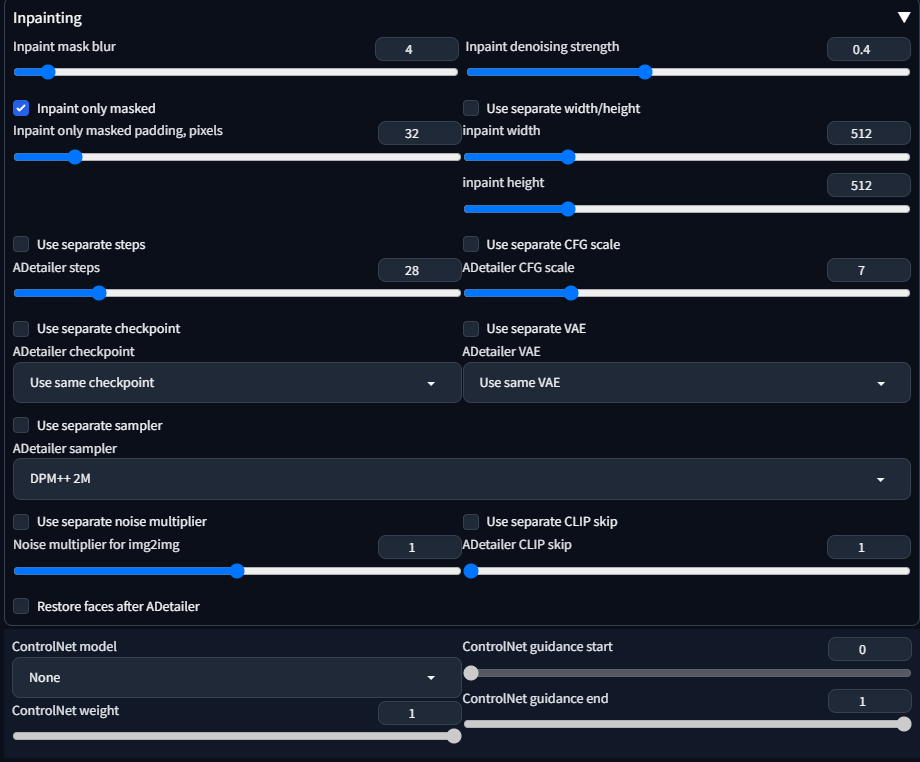
Inpaint mask blur
検出した範囲の境界のぼかし加減を決定する。0にするとぼかし部分がなくなる。
値を小さくすればするほど、加筆した箇所とそうでない箇所に境界線みたいなのが見えて目立つ。
値を大きくすればするほど、もともとの検出範囲を超えて影響を及ぼす。
いい感じの値の模索が必要。
Inpaint only masked
ON時にはマスク範囲のみの書き直しを行う。OFF時にはカンバス全体を書き直しをする。
基本的にOFFにする必要性はないと思う。
Inpaint denoising strength
書き直しの強さを決定する。
弱めると書き換え前後の違和感が少なくなるが効果が薄い。強めると効果が強くなるが前後の整合性がおかしくなることがある。
Use separate { width/height, steps, CFG scale, checkpoint, VAE sampler, noise multiplier, CLIP skip }
各種パラメータを指定して書き直しを行えます。
元画像との乖離が大きくなると、それだけ出力が破綻しやすいので、少しずつ調整するのがよいと思います。



